
PhD Thesis Final Defense to be held on November 26, 2018 at 10:00
I. Giannakopoulos Thesis Image
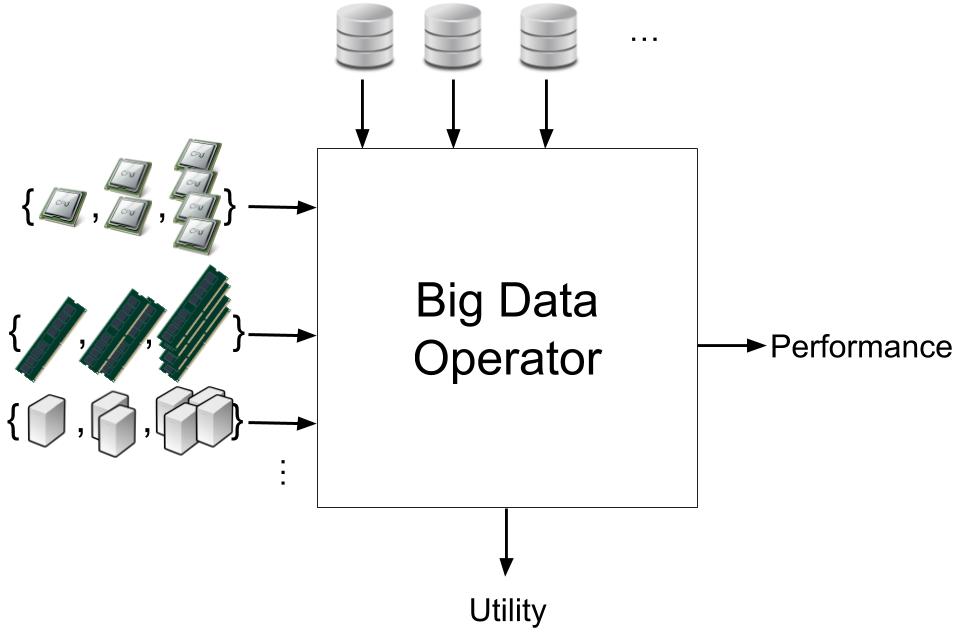
Thesis Title: Modeling Big Data Applications and Operators In Cloud Environments
The examination is open to anyone who wishes to attend (Multimedia Amphitheater, Central Library of NTUA)
Abstract
The Big Data revolution has created new requirements for the design of applications and operators that are able to handle the volume of the data sources. The adoption of distributed architectures and the increasing popularity of the Cloud paradigm has complexed their structure, making the problem of modeling their behavior increasingly difficulty. Moreover, the wide variety of the existing datasets have complicated the problem of selecting the appropriate inputs for a given operator, since the examination of the data utility for a given workflow is a largely manual process that requires exhaustive execution for the entirety of the available datasets. This thesis attempts to model the behavior of an arbitrary Big Data operator from two different viewpoints. First, we wish to model the operator’s performance when deployed under different resource configurations. To this end, we present an adaptive performance modeling methodology that relies on recursively partitioning the configuration space in disjoint regions, distributing a predefined number of samples to each region based on different region characteristics (i.e., size, modeling error) and deploying the given operator for the selected samples. The performance is, then, approximated for the entire space using a combination of linear models for each subregion. Intuitively, this approach attempts to compromise the contradicting aspects of exploring the configuration space and exploiting the obtained knowledge through focusing on areas with higher approximation error. Second and in order to accelerate data analysis, we wish to model the operator’s output when deployed over different datasets. Based on the observation that similar datasets tend to affect the operators that are applied to them similarly, we propose a content-based methodology that models the output of a provided operator for all datasets. Our approach measures the similarity between the different datasets in the light of some fundamental properties commonly used in data analysis tasks, i.e., the statistical distribution, the dataset size and the tuple ordering. These similarities are, next, projected to a low dimensional metric space that is utilized as an input domain by Neural Networks in order to approximate the operator’s output for all datasets, given the actual operator output for a mere subset of them. Our evaluation, conducted using several real-world operators applied for real and synthetic datasets, indicated that the introduced methodologies manage to accurately model the operator’s behavior from both angles. The adoption of a divide-and-conquer approach that equally respects space exploration and knowledge exploitation for the performance modeling part, proved to be the main reason that our scheme outperforms other state-of-the-art methodologies. On the same time, the construction of a low dimensional dataset metric space for the second part, proved to be particularly informative in order to allow Machine Learning models to approximate operator output for a wide variety of operators with diverse characteristics.
Supervisor: Nectarios Koziris, Professor
PhD student: Ioannis Giannakopoulos