
PhD Thesis Final Defense to be held on December 19, 2019, at 12:30
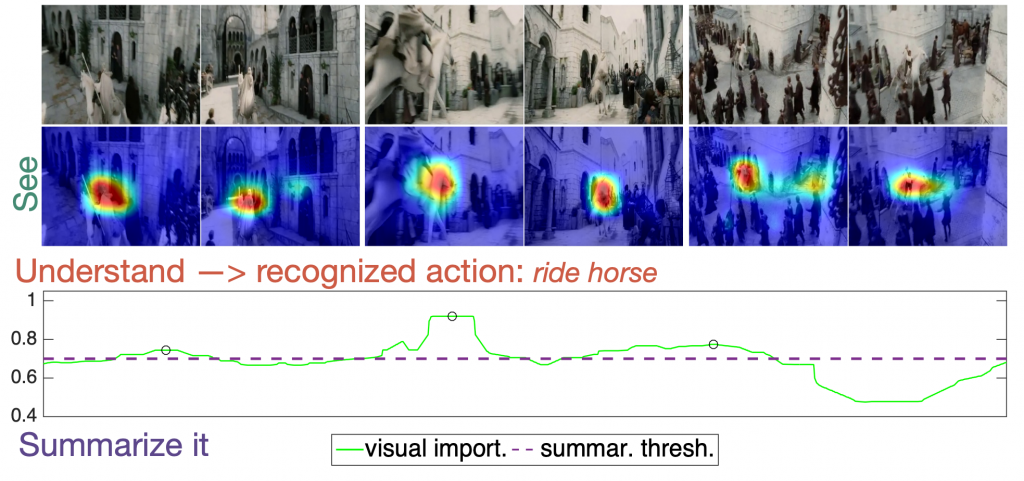
Photo Credit: Petros Koutras
The examination is open to anyone who wishes to attend (Room 1.1.1, Old ECE-NTUA Building)
Thesis Title: Learning spatio-temporal representations and visual attention modeling in computer vision applications
Abstract: During the Ph.D. thesis, there was developed and proposed a perceptually inspired spatio-temporal model for video analysis and visual saliency, that was employed and and evaluated in the spatio-temporal problems of visual saliency (by predicting the fixation points in video stimuli), action recognition and video summarization. This spatio-temporal model can provide motion information in different scales and directions without having to process it as a separate cue or use a small number of video frames. In this way, the proposed approach achieves to detect both the fastest changes in the video stimuli (e.g. flicker) and the slowest motion changes related to actions or salient events recognition.
Nowadays, the extensive usage of Convolutional Neural Networks (CNNs) has boosted the performance throughout the majority of tasks in computer vision, such as object detection or semantic segmentation. However, the progress of CNN architectures, design, and representation learning in the video domain is much slower, and the performance of deep learning methods remains comparable with non-deep ones.
Towards this direction, this Ph.D. proposes a multi-task spatio-temporal network, that can jointly tackle the spatio-temporal problems of saliency estimation, action recognition and video summarization. The proposed approach employs a single network that is jointly end-to-end trained for all tasks with multiple and diverse datasets related to the exploring tasks. The proposed network uses a unified architecture that includes global and task specific layer and produces multiple output types, i.e., saliency maps or classification labels, by employing the same video input. From the extensive evaluation, on seven different datasets, we have observed that the multi-task network performs as well as the state-of-the-art single-task methods (or in some cases better), while it requires less computational budget than having one independent network per each task.
In parallel with the proposed models for spatio-temporal representations learning, there were also investigated additional methods for tackle each one of the above spatio-temporal problems independently that outperform the existed state-of-the-art methods in many evaluation databases. For this purpose it was developed a multimodal system for salient events detection and video summarization based on visual, audio and text modalities. The system's performance was evaluated in human annotated databases, which contain both movies and documentary videos, and manage to improve the existing summarization systems.
In the context of studying temporal related problems in computer vision, one important part of the Ph.D. has focused on extending and integrating computer vision algorithms in robotic applications and especially in human-robot interaction systems designed for specific groups, like elderly people and children. More specifically, there were developed methods and models for multi-view human action and gesture recognition by employing information from multiple sensors. The evaluation results in specific databases as well as with primary users have confirmed the success of the proposed system for human-robot interaction tasks both in terms of performance and user acceptability.
Finally, it was proposed and developed an action and gesture recognition system for human-robot interaction applications based on neural network technology. The proposed system take advantage of the higher lever information, i.e., the pose of the human body and hands, that is extracted by processing the raw visual information using state-of-the-art deep learning based methods. The evaluation results in multiple datasets, that contain both healthy users and patients, have shown that the proposed system manages to perform high accuracy recognition while its integration in robotic platform enables real-time monitoring and recognition of human activities.
Supervisor: Petros Maragos, Professor
PhD student: Petros Koutras